co_context[0]: C++高性能协程框架
co_context 是最近开发的 C++ 异步协程框架,以易用性为最高目标,尽量兼顾性能。希望从此 C++ 的异步能比 Node.js 更简单,更优雅。
co_context 是基于 Linux io_uring,I/O 走内核态协议栈,这是 co_context 努力逼近的性能上限。
做了几个小测试,性能还是比较猛的。如果别的网络框架,但凡沾上 shared_ptr,mutex,memory_order_seq_cst 等等重型工具,多半要比 co_context 慢一些。
2022/5/26 更新:
- 新增 「I/O 取消」和「超时 I/O 取消」,API 更好用了;
- 更新调度策略,redis-PING QPS 突破 50 万了;
- 重做 redis-benchmark 的实验:
- 发现后台运行 Chrome 会显著影响 CPU 调度,进而影响性能表现——关闭 Chrome;
- 发现网络代理会降低 localhost 通信的性能——关闭网络代理;
- 链式 I/O 中operator+ 的求值顺序是由编译器定义的,因此弃用,改用operator&& ;
- 毕设 co_context 通过审核了 ,过几天儿童节答辩 ~
用例速览
redis-PING_INLINE
1 |
|
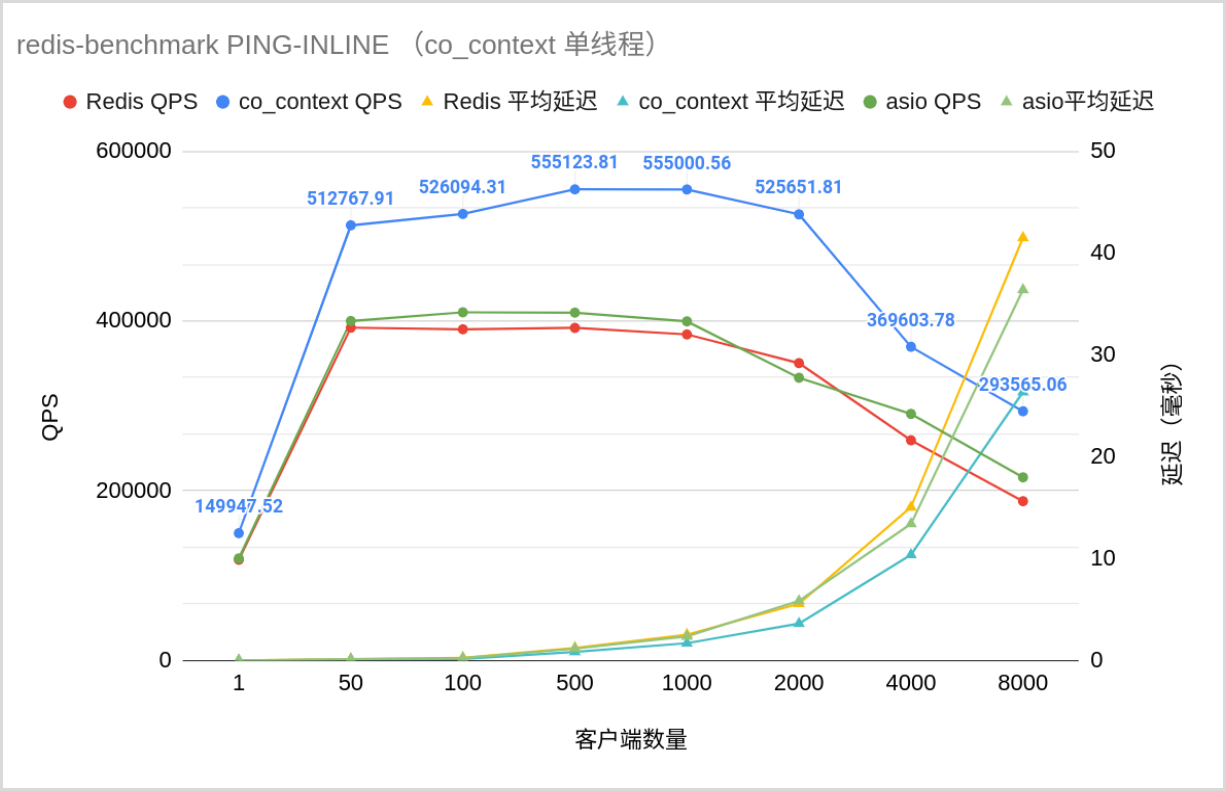
这是一个 redis-server,但无论接收什么命令,都只会返回一个"+OK"。猜猜它的 QPS 是多少?单线程下,面向 1000 个客户端,co_context QPS 是 55 万,而 redis 本尊是 36 万,平均延迟、p99延迟等均碾压。虽然……这样的性能在网络框架里勉强及格 (毕竟隔壁 bRPC 动不动五百万并发。。)。
测试工具是 redis-benchmark,其线程开1~3个(使QPS最优),测试环境是单机 5800X, 32GB 3200MHZ-ddr4。
链式 I/O
链式 I/O 能减少再入内核态和调度器的次数,增强性能。只需用&&连接请求即可。
1 | // co_await 优先级太高,须加括号 |
先做 A,然后做 B(限时 3 秒),(如果没有超时或错误)最后做 C。有错误则返回错误,否则返回 C 的结果。
一秒定时器
接下来只展示核心代码了,因为非核心代码和上面差不多。
1 | task<> my_clock() { |
每隔一秒,在屏幕上打印时间。当然,这种写法容易有累计误差,切勿模仿喔~
网络超时取消
用timeout(req, time)能够令req请求限制在time时间以内,若超时则返回失败。
1 | task<> run(co_context::socket peer) { |
对每次TCPrecv调用限时3秒钟。
I/O 取消
I/O 可以无理由取消订单,前提是货还没到你的手上。
1 | co_await cancel_fd(fd); |
取消与指定 fd 有关的 I/O 操作。
PS: 内部还可以做更细致的取消操作,只是作者还没想好怎么设计 API 比较优雅~
并发量限制
1 | counting_semaphore sem{100}; |
这段代码将业务并发量限制在 100 以内。注意counting_semaphore是针对 co_context 特制的,wait-free,性能比较好。
其他协程间同步工具
类似的同步工具还有mutex,condition_variable。所有的同步工具的使用体验和 C++ 标准定义的类似,不会有额外学习成本哦~
1 | using namespace co_context; |
上面的代码将cnt安全地递增至 1e9。
co_context 的主要内容
co_context 在 4 个方面有贡献:
- liburingcxx: io_uring 的高性能 C++ binding。
- io_context: 针对 L1 cache 的高性能调度器。
- coro: 面向用户的协程库,提供简洁、好用、符合直觉的 API,还提供了同步 syscall 的协程 API(基于同步syscall 的上层库可以快速地移植到 co_context)。
- net: 基于 coro 提供一些便捷的网络抽象(非必需)。
限于篇幅,co_context 的原理将写到其他文章中(也许就是将毕业设计报告的内容抄过来……逃)。
代码实时同步于 Github,求 star~