co_context[2]: 性能优化杂谈
Hello,我是等疾风!本篇介绍在 co_context 中用到的性能优化技巧,希望在各位 C/C++ 道友的项目上有所帮助。重点将在技巧的入门,而不是 co_context 本身。
性能分析
大多数情况下,我们其实是在优化已有的代码,而不是在设计全新的高性能业务。所以建议在优化之前,先分析出哪些代码是热点,哪些代码占用最多的运行时间/空间,然后再针对性地做优化。相关的工具有 perf,vtune,valgrind 等等。需注意性能分析工具会不会拖慢程序运行速度(例如 valgrind,好家伙直接令我的程序假死),因为这会带来测量的误差。
除了现成工具,还可以用 rdtsc 指令做低损耗、高精度的时间测量。
在 co_context 里,性能在一开始就是设计重点,所以会减轻一些总体工作量。
无锁化
细数互斥锁「四宗罪」
无锁设计,是性能优化入门的一道坎。我们在写多线程程序时,很自然想到用互斥锁(mutex)来保护共享数据,防止读到脏数据,防止竞争条件(race condition)。互斥锁还有信号量(semaphore),条件变量等变体,它们的原理都是类似的。但它们会有一些性能缺陷:
- 和线程高度绑定:如果互斥锁抢不到,线程就陷入阻塞;
- 引入额外的数据结构:至少有一条唤醒队列,记录哪些线程等待唤醒;且这条队列是不定长的;
- 和操作系统高度绑定:线程的阻塞和唤醒都要走操作系统内核态;会打断 CPU 流水线,所以极致性能优化下一般不喜欢看见内核态;
- 要切换上下文:每次切线程都要暂存和恢复寄存器的值,可能引发内存 I/O。
说了一堆屁话,总之能避开互斥锁就避开,而 co_context 比较无脑粗暴,几乎直接禁用了互斥锁。这也会带来一些副作用:线程在空闲的时候也没法阻塞,会导致 CPU 空转,对于其他进程来说无疑是 CPU 强盗。(所以我也给出了备选方案:使用 std::atomic<xxx>::wait/notify,它的原理类似 futex,线程可以阻塞)
无锁世界的秩序
无锁世界的秩序主要靠「原子变量」来维持。原子变量本质是对 CPU 内存顺序、原子指令、编译器乱序约束的封装。本节只做最基本的入门介绍,入门之后,读者可以快速读懂其他文章。
比方说,县长说他到鹅城来,只干三件事,然后就离开。这三件事涉及机密,完成之前外人没法知道其状态。有一天,县长离开了鹅城,说明「三件事」已经完成了。至于是哪件事先做完,哪件事后做完,民间众说纷纭。
在例子中,我们令「县长的位置」为原子变量,若「县长的位置」≠「鹅城」,则编译器和 CPU 保证三件「事」已经完成,但是,由于乱序优化和内存顺序等问题,这三件「事」的完成顺序是不确定的。所幸,我们不关心顺序,只要访问这三件「事」的结果就可以了。
于是,我们解锁了两种 C++ 内存顺序:std::memory_order_release 和 std::memory_order_acquire
我们结合代码举例:
1 | std::atomic<int> distance_from_e_city = 0; |
编译器会保证std::memory_order_release之前的指令不会被乱序到其之后,但是不保证do_A() do_B() do_C()之间的乱序。
对称地, 保证std::memory_order_acquire之后的指令不会被乱序到其之前,但是不保证use_A() use_B() use_C()之间的乱序。
最终,以原子变量为桥梁,我们实现了安全的共享数据访问。读者可以学习std::memory_order_seq_cst std::memory_order_relaxed 等等来解锁更多姿势。关键词:C++ 内存顺序
无锁数据结构
理解内存顺序之后,就能轻松上手无锁数据结构了。**定长单生产者单消费者队列(SPSC queue)**是一种高性能的无锁队列,它有很多约束:容量固定、只支持一个生产者和一个消费者。但它的延迟非常低,实现非常简单,只依赖内存顺序,不依赖互斥锁。co_context 用了 n 条 SPSC 队列来模拟“单生多消”和“多生单消”功能。
其实,保证越少,性能越高。SPSC 队列尚且保留了「先进先出」的队列性质,倘若抛弃队列性质,还有更猛的乱序数据结构,性能提高可逼近100%。但是,乱序性会带来太高的 debug 难度,在负载均衡上也不实用,最终还是被我弃用了。
用户态互斥锁
底层开发者可以承受没有互斥锁的不便,但不能不给应用层提供互斥锁的等价工具。co_context 给用户提供了互斥锁、信号量和条件变量,它们的 API 与 C++ 标准库几乎一致,在体验上没有差别,在实现上性能会略强,一是因为无等待且完全不经过内核态,二是因为没有引入堆内存分配。涉及的技巧比较复杂,在这里就不展开介绍了,关键词:用侵入式链表实现等待队列。这里推荐参考 cppcoro 的互斥锁实现。
cacheline 编排
常见 CPU 的内存读写都是以 64 字节为单位的,对应 CPU 的 cache 也是每 64 字节为一个「cacheline」。性能优化的必修课之一是妥善安排数据在 cache 中的位置。不妥的安排会导致以下情况:
- 伪共享(false sharing):线程 1 读写变量 a,线程 2 读写变量 b,本是老死不相往来,却偏偏让 a 和 b 处于同一 cacheline。
- 乒乓缓存(cacheline ping-ponging):常见于伪共享。变量 a 和 b 位于同一 cacheline,线程 1 只读 a,线程 2 频繁改写 b。结果,每当 b 被线程 2 修改时,线程 1 都要同步 a 所在的 cacheline,这实际上是多余的。
- 多余读写:常见于指针解引用、通讯协议。可以只用一条 cacheline 完成跨核通讯,实际却用了多条。
- cache 浪费:偷懒,无脑塞 64 字节做 padding。这是不负责任的做法,本质只是将 cache-miss 转移到其他数据上。
只要善用 C++ 的alignas关键字,针对以上问题,相信读者能想出优化的办法。
co_context 大量使用了 alignas(64)来指定结构体在 cacheline 中的位置,以优化性能。
跨核通信压缩
这一节也与 CPU cache 有关。
解引用真的有必要吗?
在多线程程序里,经常见到线程 1 写入变量 a,然后将 p=&a 告诉线程 2,最后,线程 2 读取*p 。这里大概率涉及了两条 cacheline 的同步:一条是指针 p,另一条是*p也就是变量 a。 但这真的有必要吗?
以 co_context 为例,优化前,线程 1 写入 a.type = xxx ,p = &a交给线程 2,线程 2 根据 p->type 做不同的操作。但是,由于 a.type 只有 8 种取值 ,对应二进制 3 个 bit,而变量 a 正好是按照 8 字节对齐的,a 的地址末尾 3 个 bit 必然为 0,意味着 p = &a 的末尾 3 个 bit 没有携带任何信息。那么为什么不让这 3 个 bit 存放 a.type 呢?
于是,优化后,线程 1 写入p = &a; p |= a.type = xxx; ,p 交给线程 2,线程 2 根据 p & 7 做不同的转发,全过程没有解引用 p,节省了一次 cacheline 传播。
使用 union 但不是 std::variant
(这一条建议非常激进,读者一旦使用,最好补上充足的文档)
使用 union(联合体)可以进一步压缩 struct 的体积。每当用 union 将 struct 的体积减小到 n*64,每次同步 cacheline 所传输的信息量就会提升,理论性能就会出现一次质变。
用 std::variant 也能达到压缩体积的目的,但是 std::variant 的以类型为单位的多态粒度比较粗糙,内置的异常处理也带来了性能损耗,在极致性能优化时可能会禁用(但 std::variant 满足普通项目是绰绰有余了)。
批处理请求
在 co_context 中,很容易完成一个批处理优化:
1 | // 优化前 |
上面的例子,原本要进入调度器 3 次,将 I/O 请求提交给内核态 3 次,在优化后统统变为 1 次。批处理优化的思想无论在底层还是架构层应用层都是非常实用的。
要留意的是批处理是否会对延迟造成不可接受的影响,如果为了批处理而强行等待,可能得不偿失。
小结
本篇介绍了一些 C++ 性能优化的技巧,重点是内存顺序和 CPU cache。虽然性能优化的水很深,需要大量的基础知识和经验积累,但正因此我们有机会为世界做别出心裁的贡献,坚定前行吧骚年!最后,放两张祖传的 co_context 性能测试图:
netcat 网络吞吐(单连接):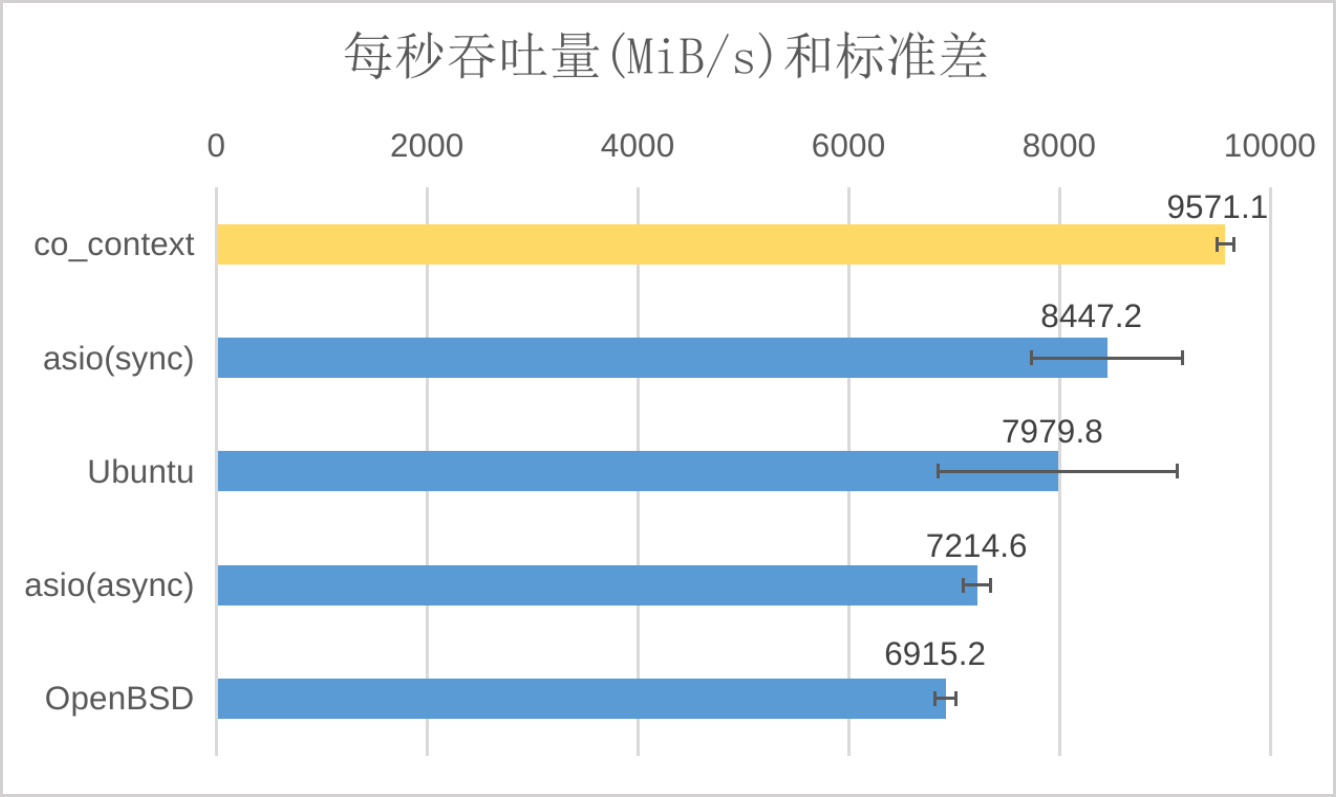
redis-benchmark QPS 和平均延迟(单线程):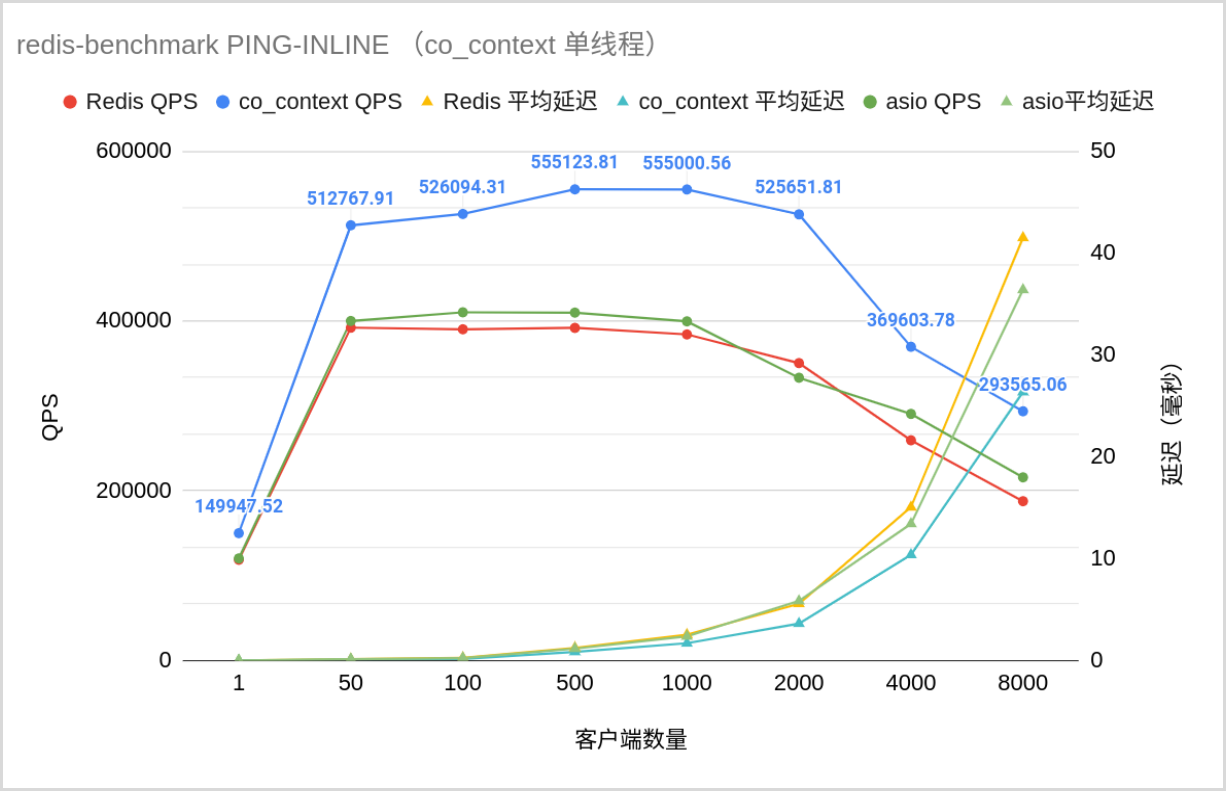
代码实时同步于 Github,求 star~